

2024-12-11

大队列研究是一种观察性研究方法,它涉及将一个明确定义的人群根据是否暴露于某个可疑因素或暴露程度的不同分为不同的亚组,然后追踪观察这些亚组的结局(如疾病发生)情况,并比较不同亚组之间结局发生率的差异,以判断这些因素与结局之间是否存在关联及其关联程度。大队列研究可以是前瞻性的,也可以是回顾性的,或者是双向的,即结合前瞻性和回顾性的特点。
大队列研究的应用领域非常广泛,包括但不限于:
生物标志物发现:识别与疾病或健康状态相关的蛋白质标志物,用于疾病早期诊断、预后评估和治疗效果监测。
疾病机制研究:通过分析疾病发展过程中蛋白质表达的动态变化,深入理解潜在的生物学机制。
精准医学:结合个体的蛋白质表达谱,制定个性化的治疗方案和预防策略。
大队列研究在精准医学和大数据时代尤为重要,它有助于揭示疾病的病因、评价预防效果、揭示疾病的自然史、掌握人口健康状况、引导实验设计,将知识转化为临床和人群早期诊断和干预策略,从而提高疾病的防治水平,降低社会卫生负担。随着各组学、大数据科学、分子影像等新技术的不断纳入,大队列研究在疾病精准的预防、诊断和治疗方面发挥着越来越重要的作用。
 doi.org/10.1016/j.jhep.2024.03.035
doi.org/10.1016/j.jhep.2024.03.035
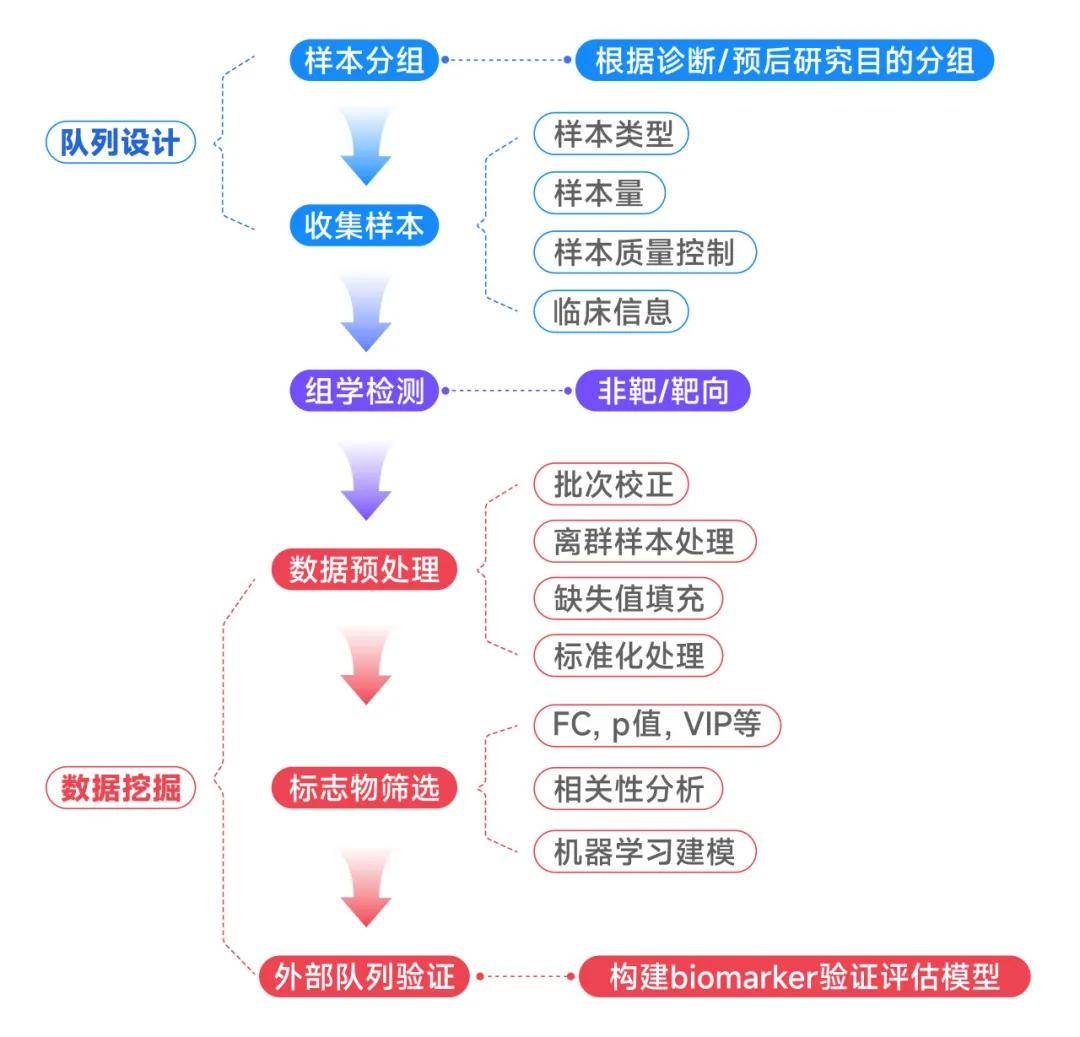
在队列设计中需要注意许多关键要点,以免样本检测完成后影响biomarker的筛选。那么队列研究设计的关键点有哪些?
关键点1---队列样本如何分组?纳入纳排很重要!
(1)根据科学问题进行组间设置,根据现有临床指南中相关疾病现有诊断指标对人群样本进行明确的分组,通常包括健康组和疾病组,在疾病组中根据不同的研究目标来分亚组。例如研究疾病的早期诊断biomarker,需要在疾病组中区分出早期患者及中晚期患者两个亚组,以及加上其他阳性对照以明确biomarker的特异性。
(2)如果研究疾病治疗效果的biomarker,不仅需要设置治疗患者前后的样本,也需要加入健康人样本的分组,在后续筛选biomarker中以排除其他因素引起的生物标志物变化,提高biomarker的敏感度和特异性。
(3)筛选代谢标志物的队列设计中,在所有样本的纳排中需要去除携带其他代谢影响的患者样本,以排除其他疾病带来的代谢影响,引起biomarker筛选的假阳性。
关键点2---样本对应记录的临床信息需要全面
(1)在收集样本的同时需要相应的临床信息全面,缺失信息的样本在后续的分析中会被剔除或者难以分析其异常原因。
(2)在后续的biomarker筛选时一般会用到组学数据和临床数据进行联合分析,缺失临床信息给分析带来了巨大难度。
(3)利用多批次验证biomarker的过程中,需要多批次的样本临床基线基本一致,以避免由于临床基线差异引起的组学结果差异,影响biomarker的验证效果。
关键点3---样本及样本量的选择
(1)在设置每组样本量的过程中,由于人群饮食生活习惯的不同会存在个体异质性,因此队列设计中每组样本最好大于30例以上。
(2)在队列筛选biomarker的过程中通常会用到机器学习的方法,因此建议加大样本量,对于大队列的多中心筛选验证biomarker中通常建议每组大于70例,提高biomarker筛选的敏感度和特异性。
(3)血样避免反复冻融以及溶血,使得检测的结果引起偏差。
关键点4---不同类型样本需要同一患者来源
用血液样本筛选biomarker的同时,一般会结合组织样本来验证和辅助筛选,需要挑选血液样本和组织样本来源于同一患者,切记不要选择同一种疾病不同人来源的样本,会带来分析难度,增加其他因素引起的差异。
关键点5---数据挖掘分析
(1)队列样本的数据分析中首先需要做数据的预处理,不同批次样本的缺失值填充需要使用同一的填充方式。
(2)不同批次间保持临床基线的一致,避免临床基线不同带来的差异影响。
(3)离群点的处理需要结合临床信息确认是否异常进行样本去除。
(4)在机器学习建模过程中可以使用多种机器学习的方法,来筛选最佳模型得到诊断性能高的biomarker。
(5)在筛选过程中可以选择和疾病临床指标相关性比较高的标志物提高筛选效率,也可以结合临床指标作为共同的生物标志物panel来对疾病进行诊断和预后。
临床队列Biomarker筛选技术路线简图
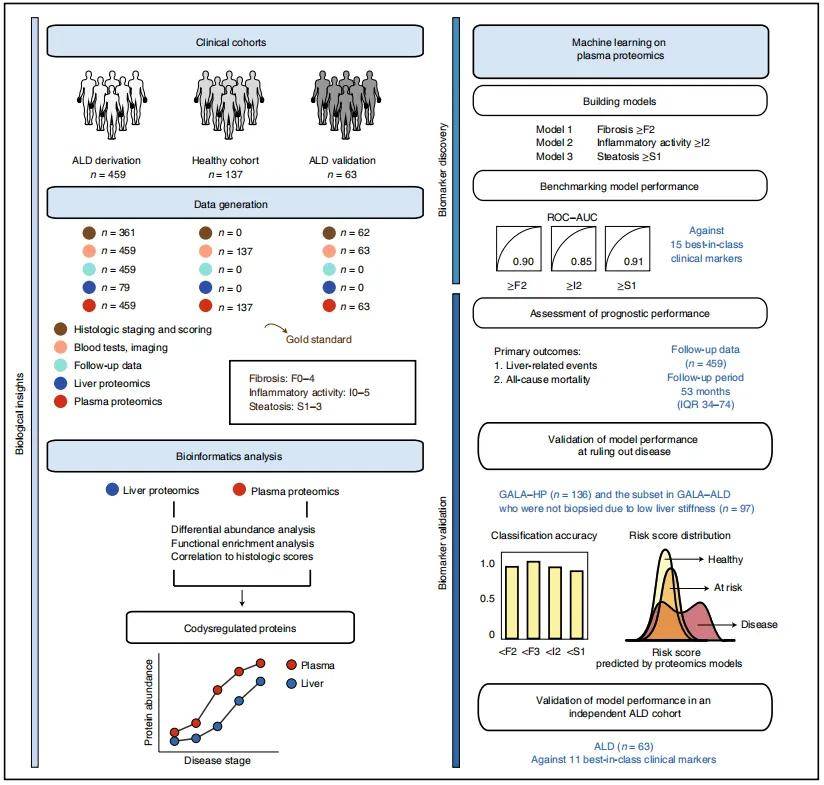
大队列高分文章案例
文章题目:Noninvasive proteomic biomarkers for alcohol-related liver disease
期刊:Nature Medicine
影响因子:58.7
研究背景和结论:
酒精性肝病(ALD)是世界肝脏相关死亡的主要原因,但对该疾病的三个关键病理特征(纤维化、炎症和脂肪变性)的了解仍不全面。本研究使用配对的肝脏-血浆蛋白质组学方法来推断分子病理生理学,并探索血浆蛋白质组学在596例个体(137例对照组和459例ALD患者)中的诊断和预后能力,其中360例进行了活检组织学评估。使用蛋白组学分析了所有血浆样本和79例肝脏活检。在血浆和肝活检组织中,代谢功能下调,而纤维化相关信号和免疫反应上调。机器学习模型确定的蛋白质组学生物标志物panel比现有的临床检测(DeLong’ test,p < 0.05)更准确地检测出显著纤维化(ROC-AUC:0.92,准确性:0.82)和轻度炎症(ROC-AUC:0.87,准确性:0.79)。研究发现,这些生物标志物组可预测未来肝脏相关事件和全因死亡率,其C-index指数分别为0.90和0.79,外部独立验证队列验证了此诊断模型的性能。
希望小派本次的大队列设计要点给您带来新的启发,助力大队列biomarker的方案设计,在未来的队列研究中更加游刃有余!


















